Method Overview
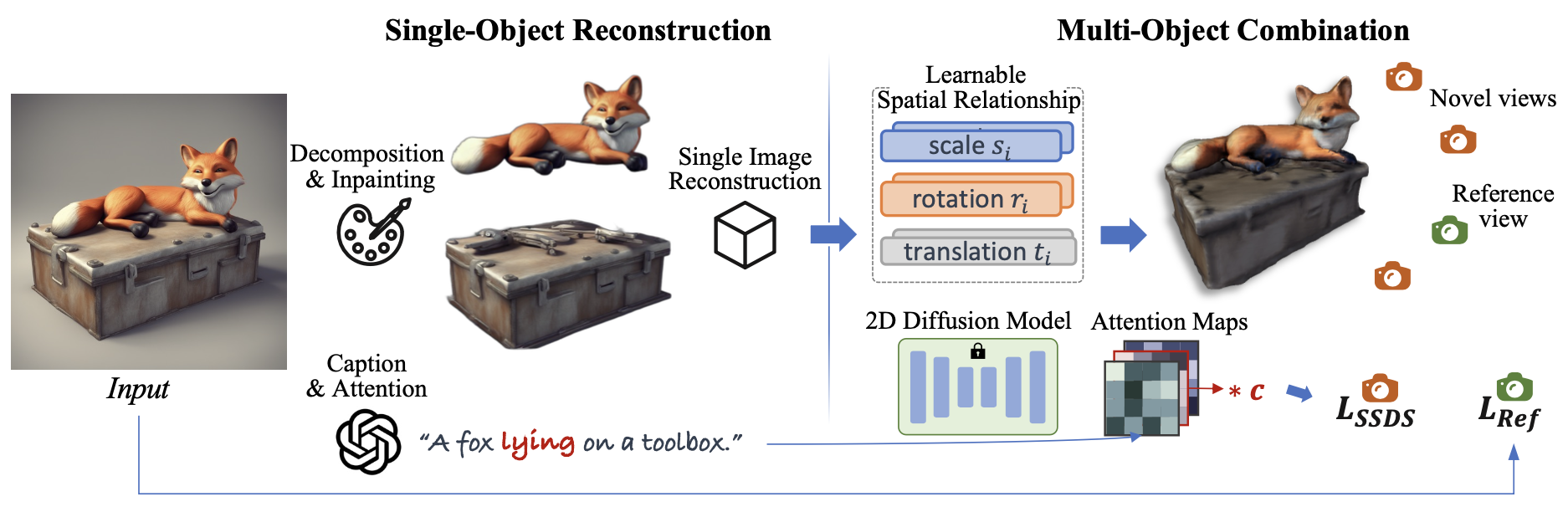
Overview of ComboVerse. Given an input image that contains multiple objects, our method can generate high-quality 3D assets through a two-stage process. In the single-object reconstruction stage, we decompose every single object in the image with object inpainting, and perform single-image reconstruction to create individual 3D models. In the multi-object combination stage, we maintain the geometry and texture of each object while optimizing their scale, rotation, and translation parameters.