TANGO: Text-driven PhotoreAlistic aNd Robust 3D Stylization via LiGhting DecompOsition

News
🏆 [Nov 11th 2022] TANGO was selected in NeurIPS spotlight papers.
Abstract
Creation of 3D content by stylization is a promising yet challenging problem in computer vision and graphics research. In this work, we focus on stylizing photorealistic appearance renderings of a given surface mesh of arbitrary topology. Motivated by the recent surge of cross-modal supervision of the Contrastive Language-Image Pre-training (CLIP) model, we propose TANGO, which transfers the appearance style of a given 3D shape according to a text prompt in a photorealistic manner. Technically, we propose to disentangle the appearance style as the spatially varying bidirectional reflectance distribution function, the local geometric variation, and the lighting condition, which are jointly optimized, via supervision of the CLIP loss, by a spherical Gaussians based differentiable renderer. As such, TANGO enables photorealistic 3D style transfer by automatically predicting reflectance effects even for bare, low-quality meshes, without training on a task-specific dataset. Extensive experiments show that TANGO outperforms existing methods of text-driven 3D style transfer in terms of photorealistic quality, consistency of 3D geometry, and robustness when stylizing low-quality meshes.
Method
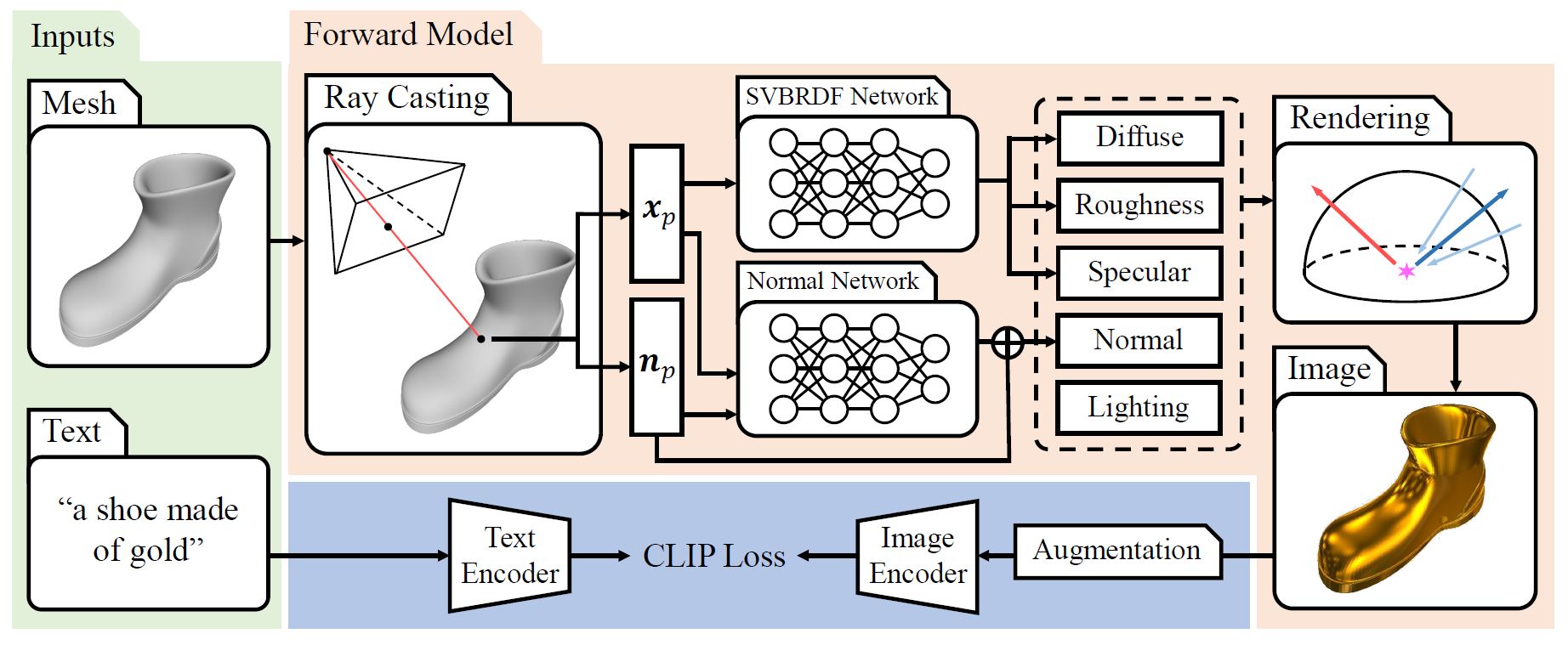
Given a scaled bare mesh and a text prompt (e.g., “a shoe made of gold” as in this figure),
we first specify a camera location c and cast rays R to intersect with the given mesh. For each
intersecting camera ray, we obtain a surface point xp and normal np, which are used for predicting
spatially varying BRDF parameters and normal variation by two MLPs, i.e., the SVBRDF Network
and Normal Network. Meanwhile, the lighting is represented using a series of spherical Gaussians
parameters {μk, λk, ak}. For each iteration, we render the image using a differentiable SG renderer
and then encode the augmented image using the image encoder of a CLIP model, which backpropagates
the gradients to update all learnable parameters.
Neural stylization
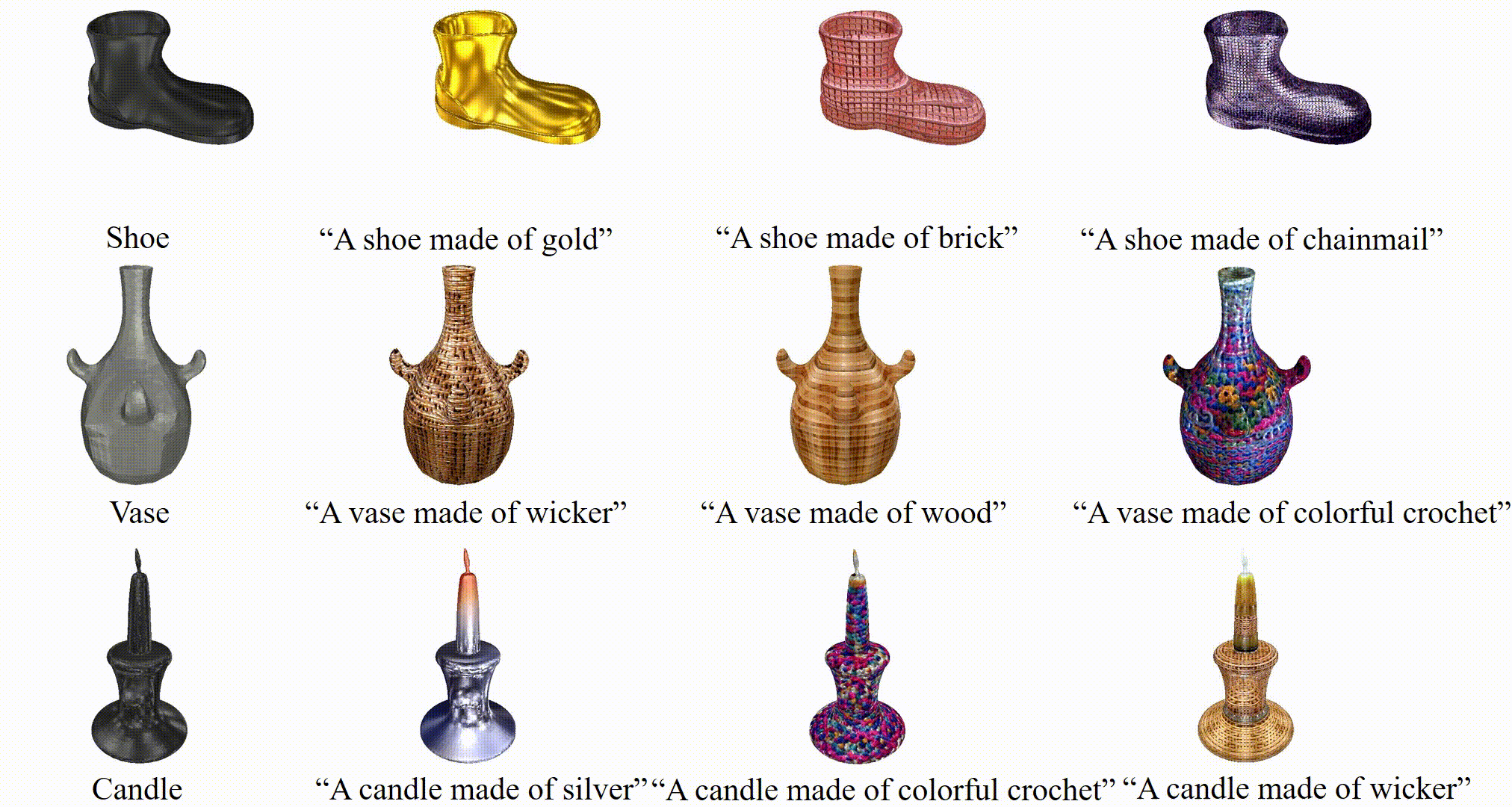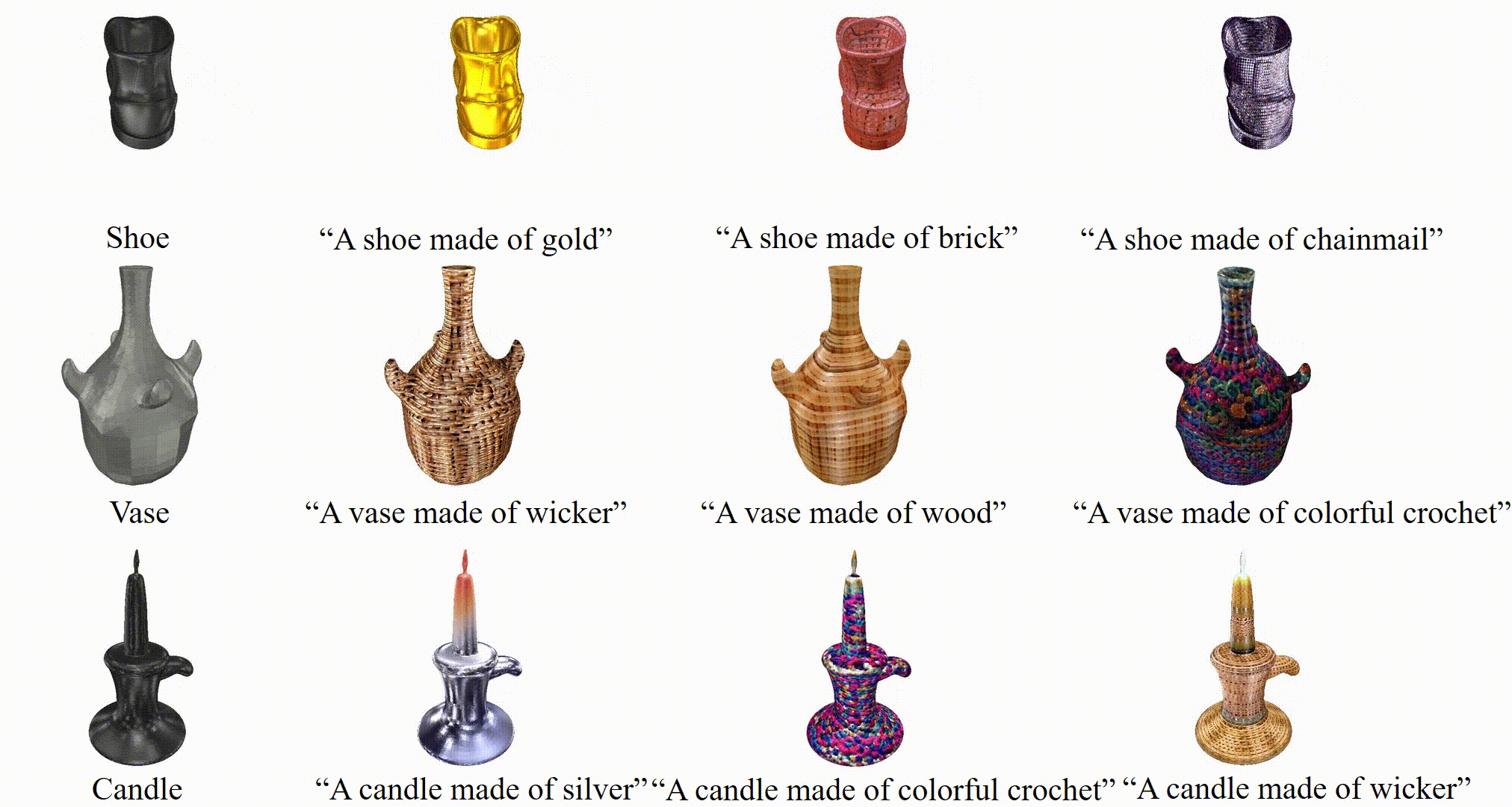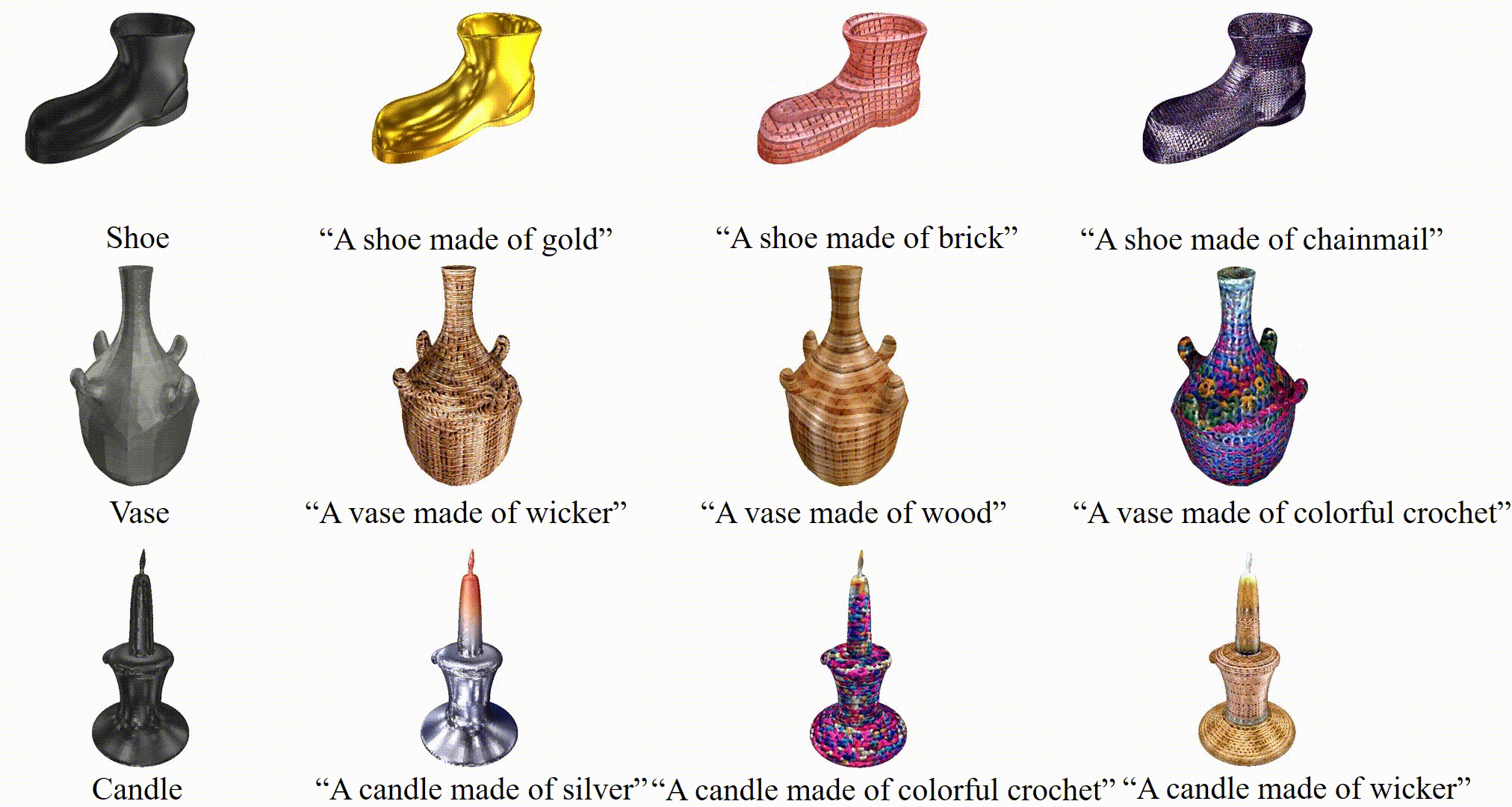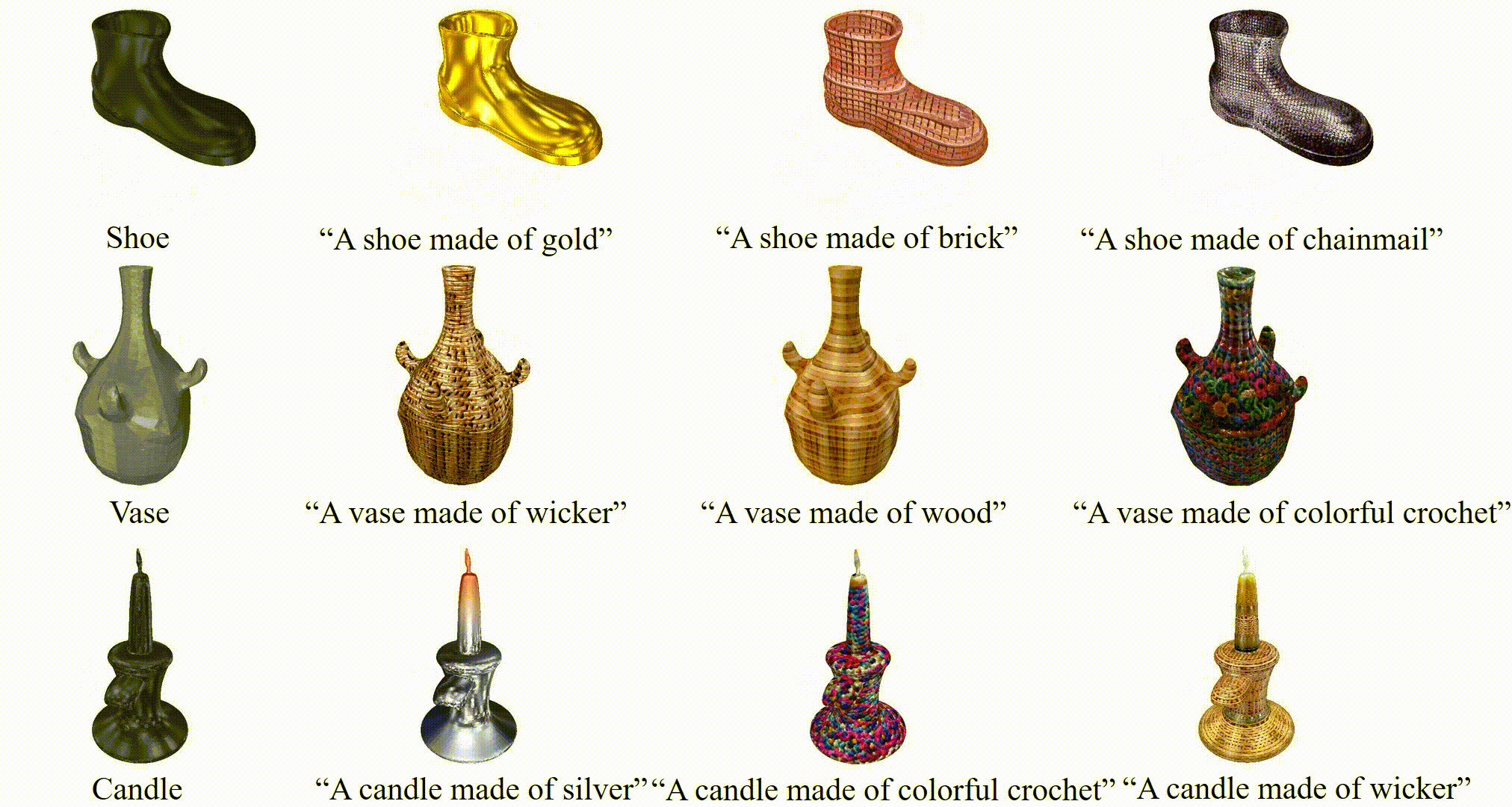
3D stylization results of TANGO given a bare mesh and text prompt.
Disentanglement

An illustration of the disentangled rendering components. This figure shows (a) our final rendering result of “A shoe made of brick” and individual components for the rendering including (b) the original normal map of input mesh, (c) the normal map predicted by TANGO, (d) diffuse map predicted by TANGO, (e) spatially varying roughness map, (f) spatially varying specular map and (g) environment map. Note that the BRDF is composed of the diffuse map, roughness map, and specular map.
Relighting

An illustration of the relighting performance. The left image shows our rendering result and estimated environment map of “A vase made of wood”, while the following three ones are relighted results with different environment maps downloaded from the Internet.
Material Editing

An illustration of the material editing performance. In each line, we increase the roughness value of the material, while we increase the specular value in each column. We can observe that the surface becomes more diffuse as we enlarge the roughness, while increasing the specular value results in more shiny surfaces. This illustration justifies the capability of TANGO on editing the material.
Robustness Comparison
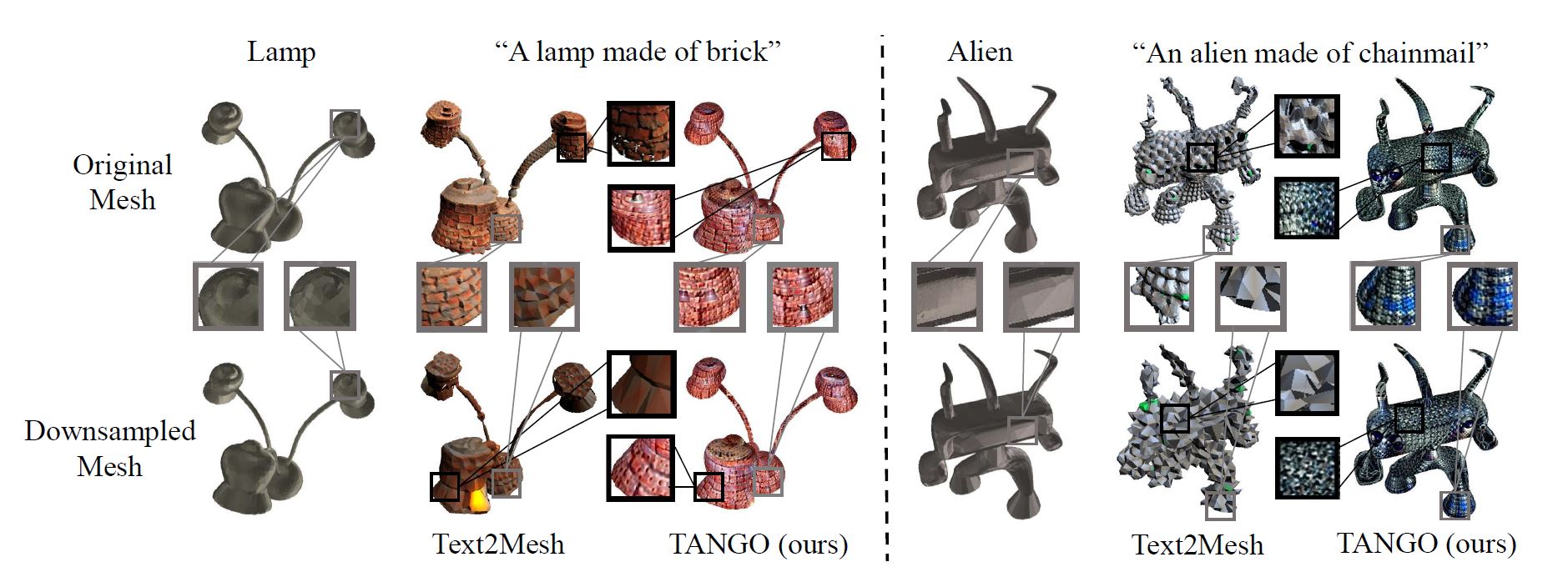
A robustness comparison of TANGO and Text2Mesh on high-quality meshes (cf. the top row) and downsampled meshes (cf. the second row). The results of Text2Mesh degenerate significantly as the mesh quality downgrades, while TANGO presents consistent results on meshes of various qualities.
Ablation Study
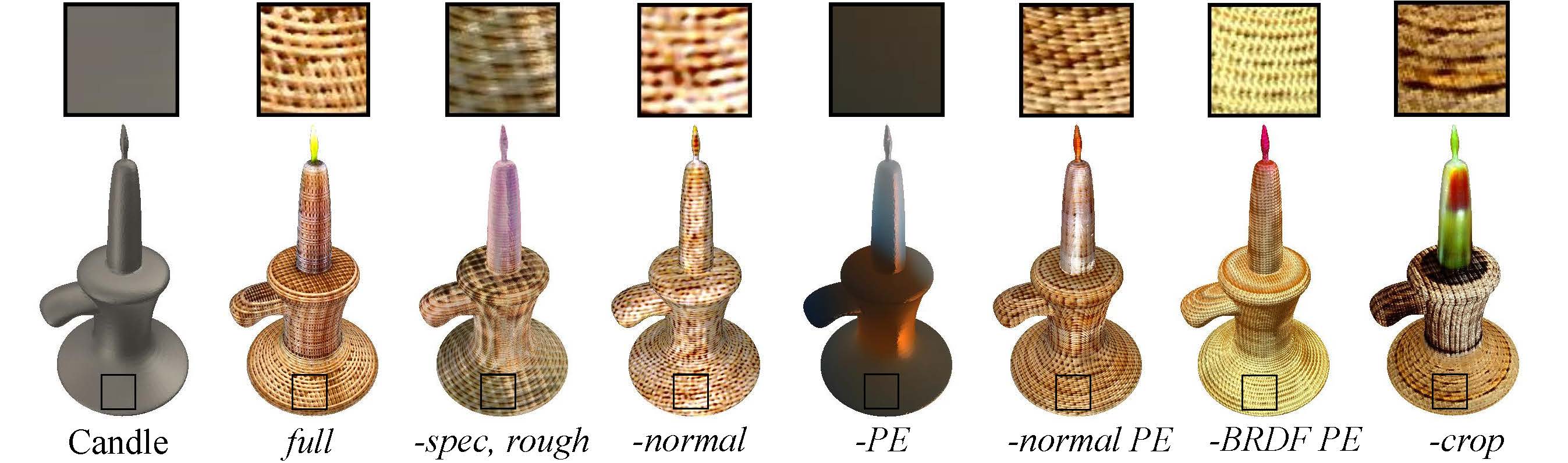
Ablation experiments on the proposed modules in TANGO, where the text prompt is “A candle made of wicker”.
Citation
@article{chen2022tango,
title={Tango: Text-driven photorealistic and robust 3d stylization via lighting decomposition},
author={Chen, Yongwei and Chen, Rui and Lei, Jiabao and Zhang, Yabin and Jia, Kui},
journal={Advances in Neural Information Processing Systems},
volume={35},
pages={30923--30936},
year={2022}
}